A framework for initiative planning
The goal of this document is to arm you with a framework you can use to plan an initiative. You will start with a vision and end with a strategy.
Context
A fundamental skill of working in the software industry — and one could argue a fundamental life skill — is being able to set a goal (your vision) and trace a path to get there (your strategy). This skill is required in your daily work in multiple areas and in various scales of complexity and ambiguity; be it a Jira ticket, a team's epic, a cross team initiative planning.
Granted, most of the work you do day to day is straightforward enough that you unconsciously plan and execute it without giving it a second thought. But a time always come where you need to work through something complex, and doing it haphazardly becomes a non option.
However, such planning skills are seldom taught and usually learned by trial, error, and observation. As engineers, we are not given a framework or methodologies to follow that can transform a vision into an actionable strategy.
This document aims to remediate this lack of actionable frameworks. It is a guide on how to approach the planning of an initiative in a structured way. It helps you not only identify the steps you need to take to get there, but gives you the necessary information to plan the milestones you need to hit and how to coordinate the team to avoid dependencies and blockers between engineers.
The framework
"What needs to be true so X is true?" — that is the question you need to answer when planning an initiative.
When planning an initiative, you know where you are (what you have in place, your starting point) and where you want to be (what you will have in place, your finish line). But the path to get from A to B is usually fuzzy. How do you start thinking about this? Do you need a new service? What features need to be in place? What depends on what? How do you know what is a must for launch and what is not?
You start at the end and make your way backwards until you find your starting point.
This framework relies on a quirk of how our minds work (or maybe it's just mine?): spelling out the next step is always harder than spelling out what is right behind us. Instead of starting from where we are and trying to blindly find our way to the end, we start at the end and outline the steps we took to get there.
It's a similar approach from navigating a maze backwards. There are less permutations of the path when you start where you want to finish and work backwards.
If this approach doesn't make sense yet, don't worry. The next section will walk through the planning of an initiative step by step.
A practical example
Context
A financial company's Customers have become an increasingly interesting target for fraudsters in the last months. Despite all the effort being put into stopping frauds from happening in the platform, there is always a chance that malicious users will get through the barriers and commit an illegal act. At that point, the only thing we can do is to identify and stop the fraudster. The goal of this initiative is to create a system that can listen to signals from the platform and alert us and the Customers that something suspicious is happening.
Planning a Platform Watcher
Start at the end
As mentioned before, you start at the end. Write down what your goal is with the initiative.

What needs to be true so suspicious activity in the platform is notified?
Remember the question from up there? What needs to be true so X is true?
If suspicious activity in the platform is notified, that means that we are notifying it to ourselves and Customers, right? It might seem silly, but write it down.
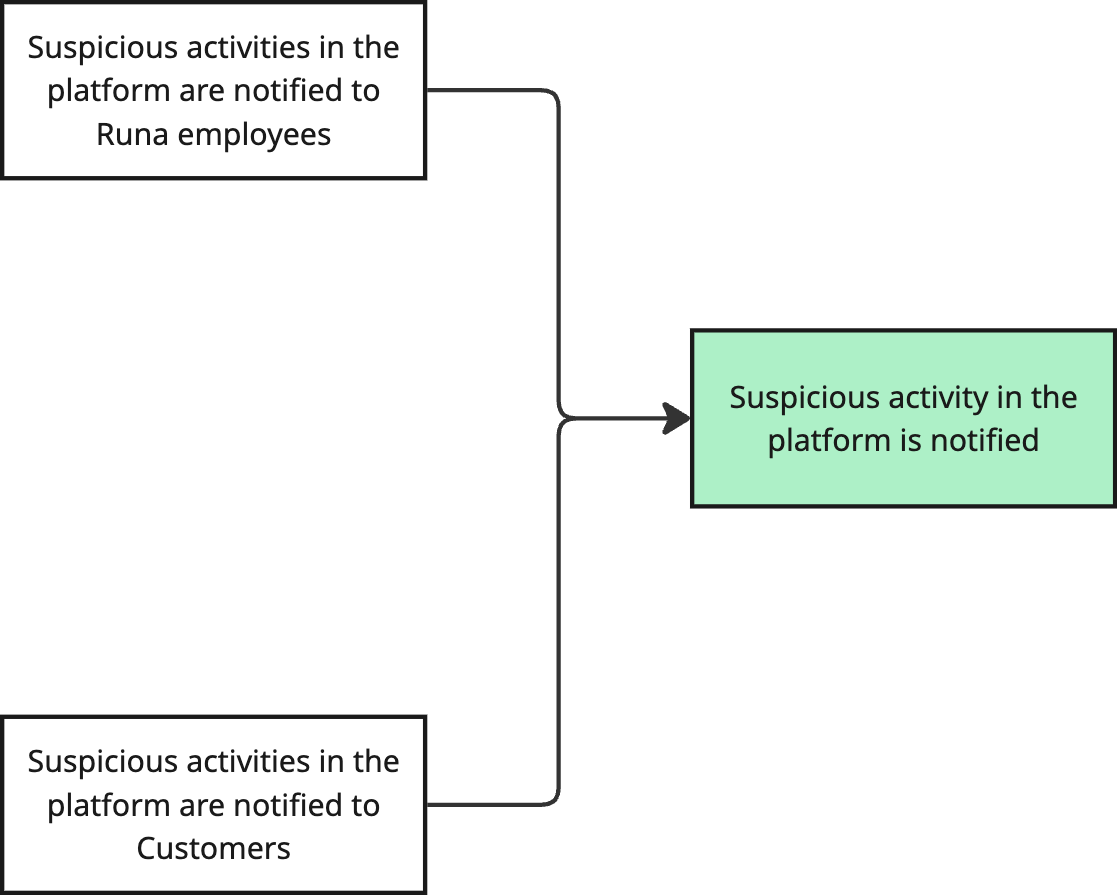
Having these two paths means that we can isolate them from each other and can prioritise the work that goes into them accordingly. Don't be afraid if things feel too small or too big, just write them down and review them later.
At this point, we can't split our minds in two (though I'd love to) and describe the previous step for both at the same time. So we will pick one of them and go for it. We can later come back and think about the other one.
What needs to be true so Customers are notified?
For Customers to be notified, we need to know who to notify, right? Will it be the CEO? The finance team? Perhaps the engineers! Whoever it is, it will be different for every company, and we need to be able to configure it.
But not only that, so far we know who to notify, but when will we notify them? We need to be able to identify that something is going wrong in our platform. Let's write these two down.
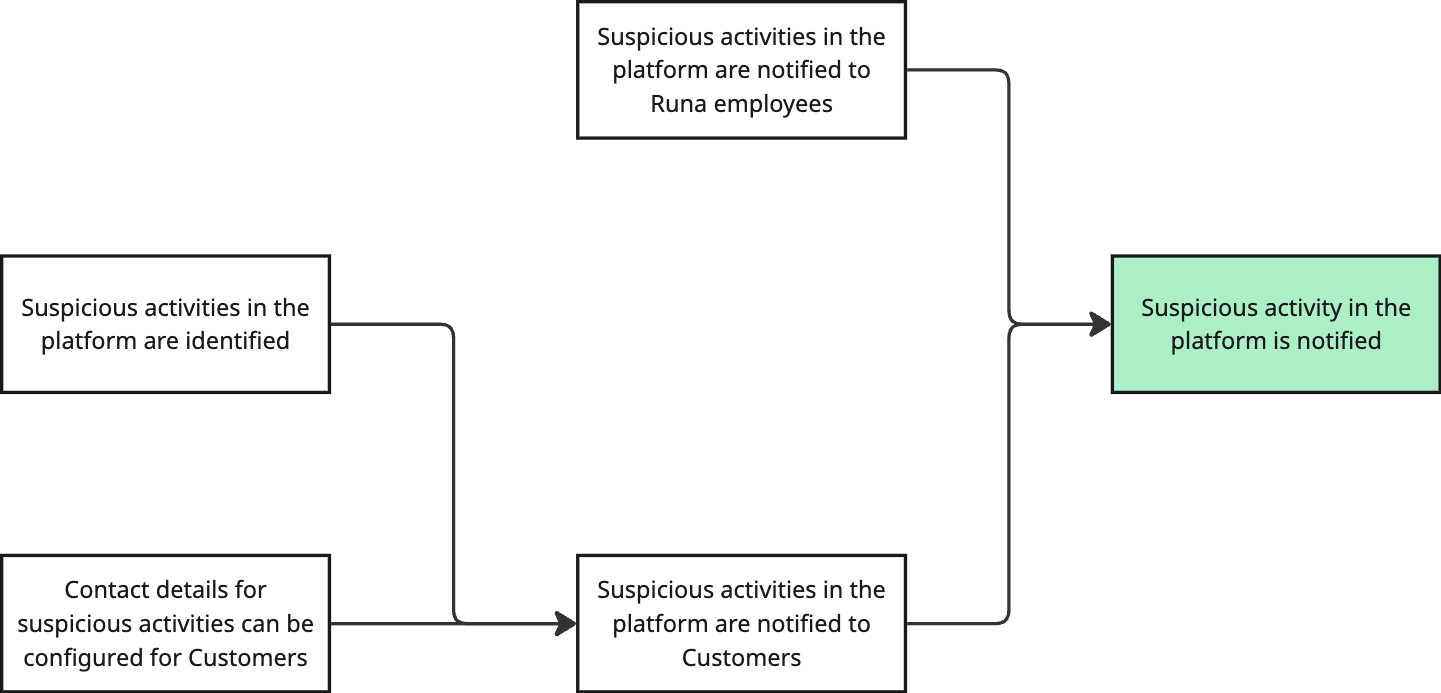
Noticed something? Identifying that something suspicious is going on is also a pre-requisite to notifying the company's employees. So let's add that in.
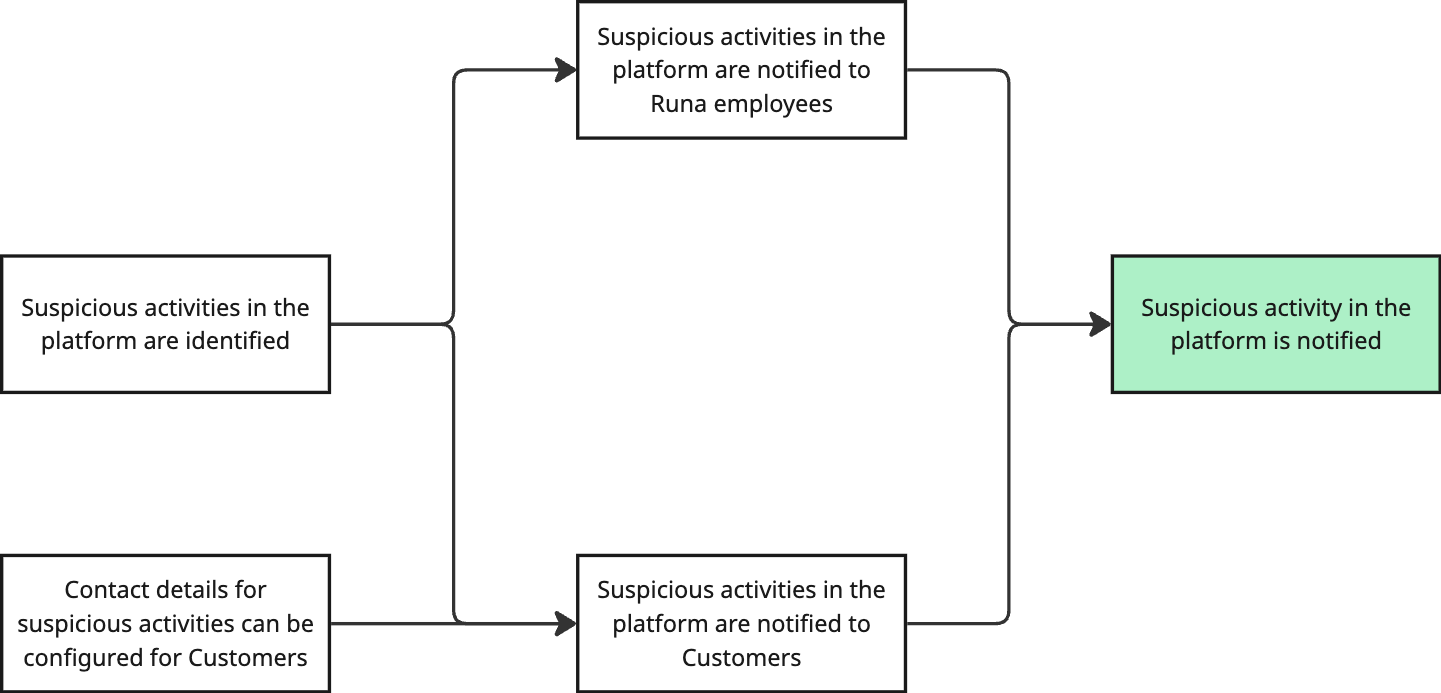
What needs to be true so suspicious activities are identified?
If it's true that we are identifying suspicious activities in the platform, that means that we have things in place that allow us to identify them, right? What could that be?
Answer: an algorithm for analysis and thresholds.
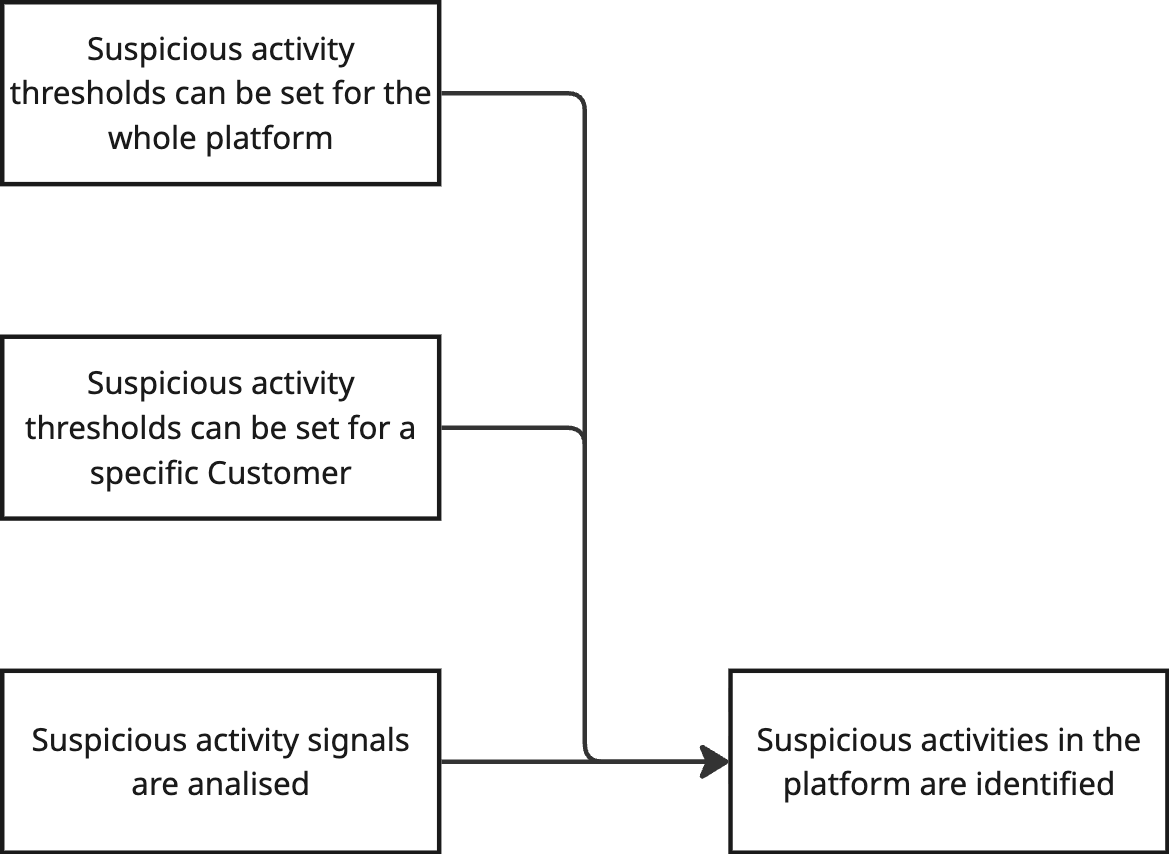
What needs to be true so we can perform our analysis?
We need data, right? We can't analyse anything without data.
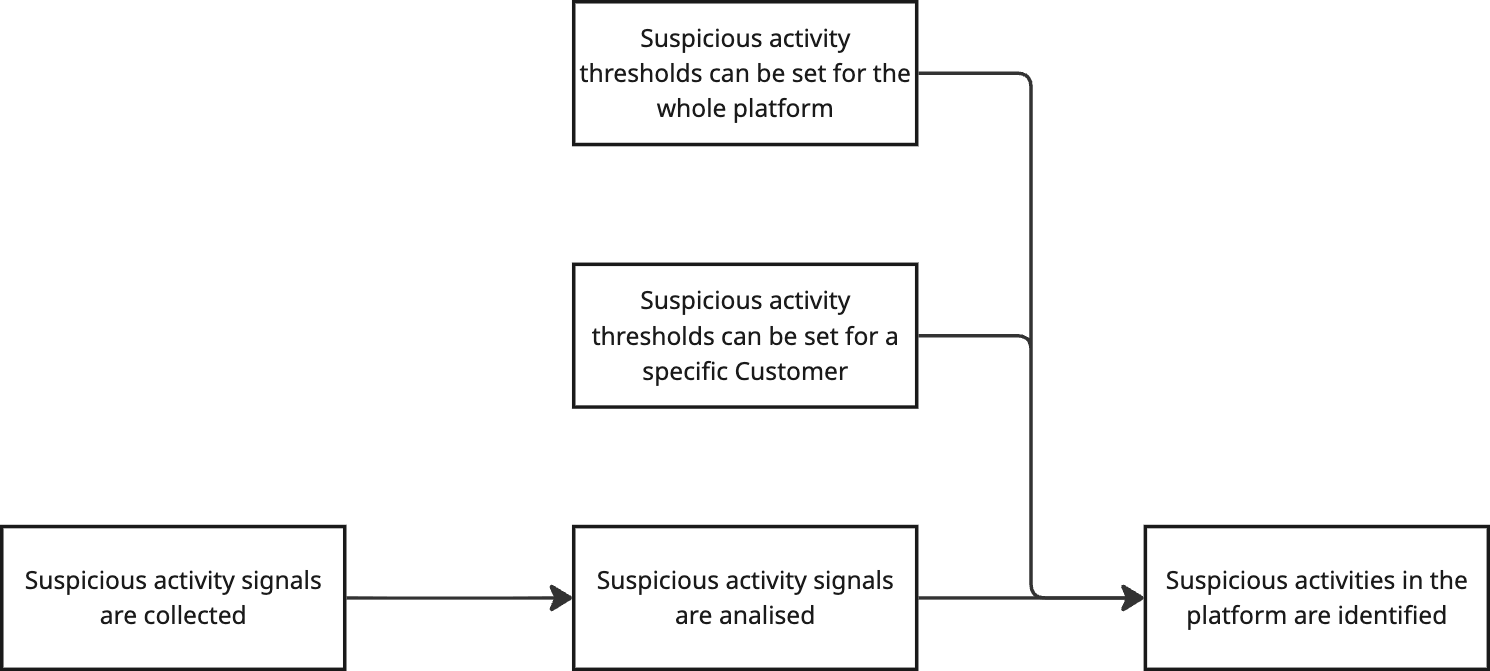
What needs to be true so we can collect data?
To collect data, the Platform Watcher needs to receive data from all the corners of our platform. Some of this data might already be collected, some might not. All of this needs to be represented in our diagram.
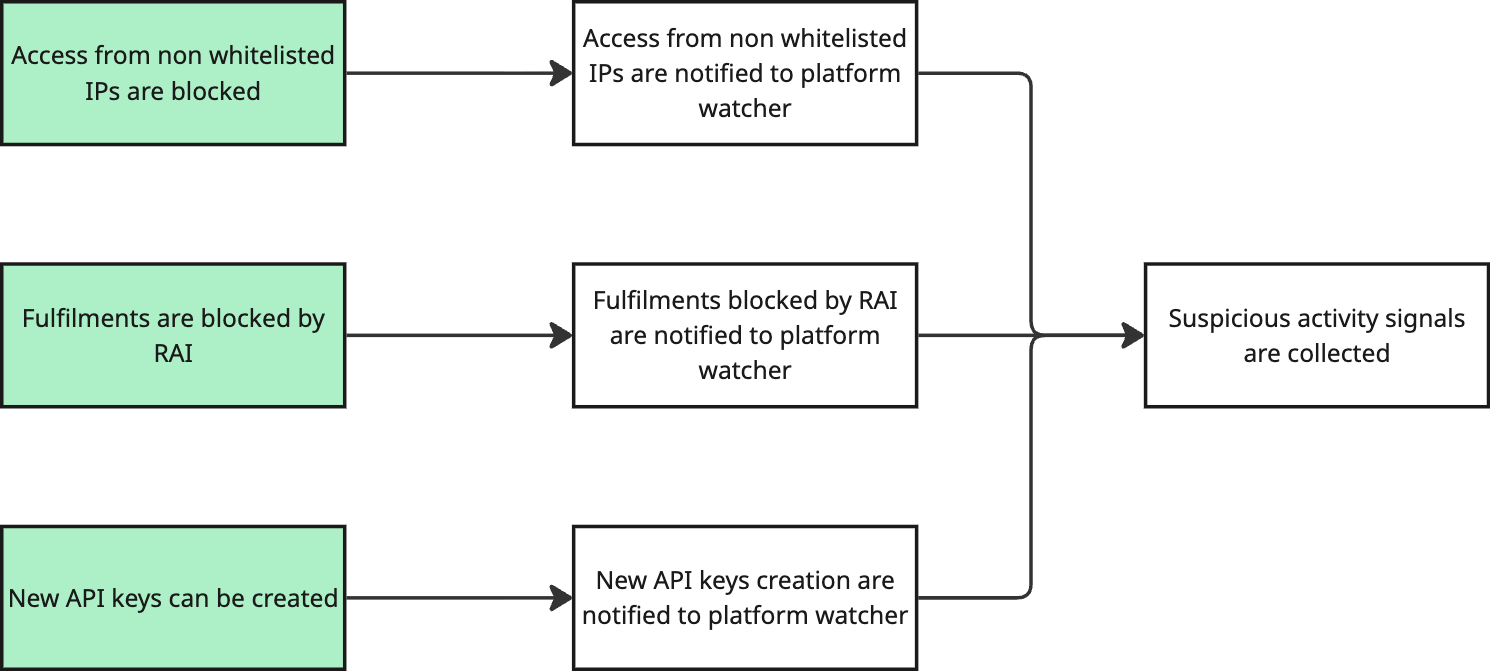
We then mark in green the boxes that are already true in our platform. These are our starting points.
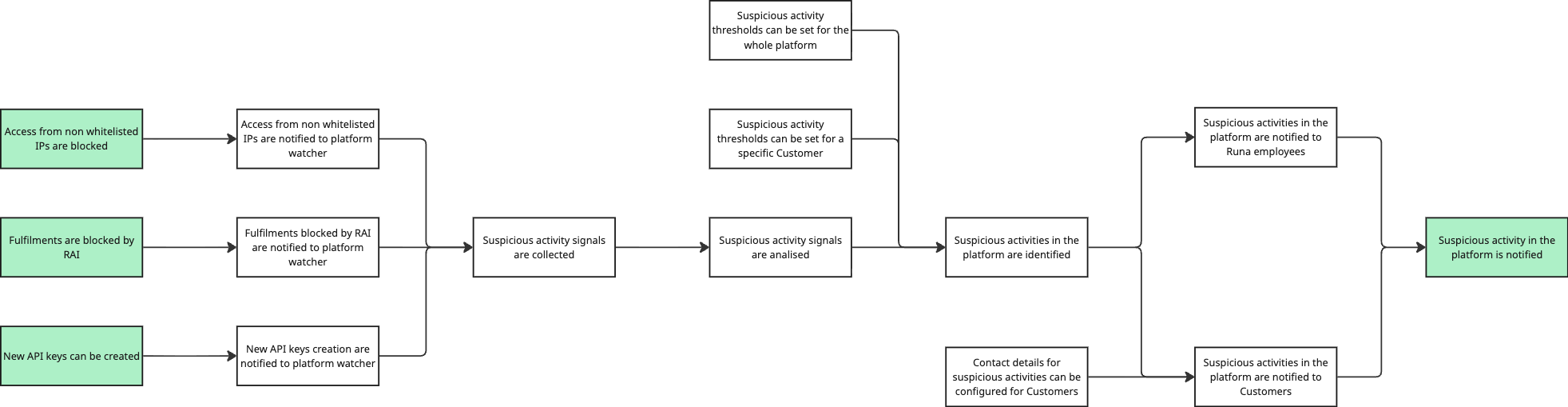
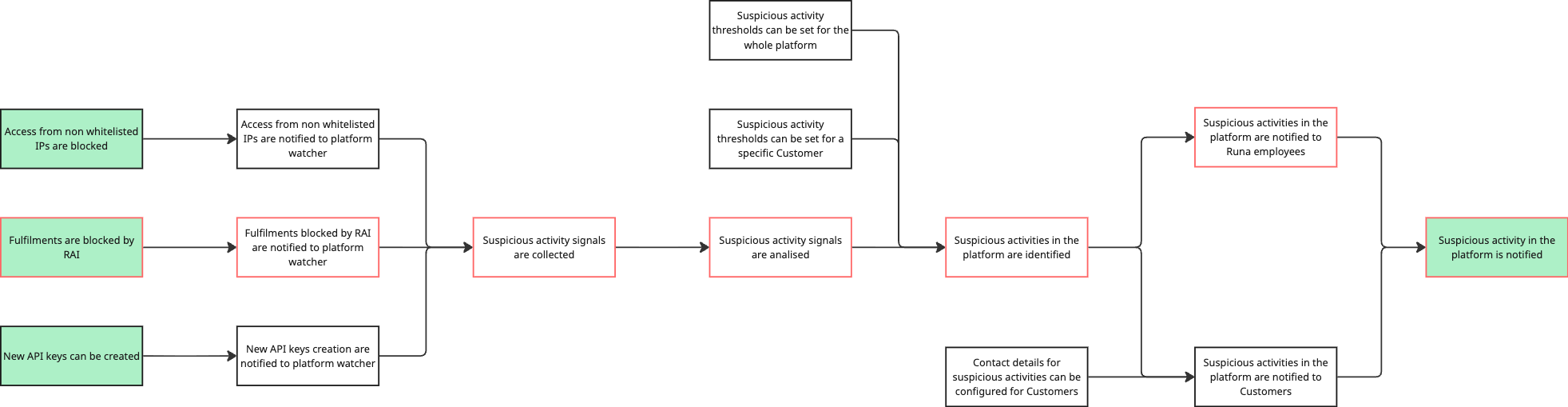
The full picture
In the image below you can see the full diagram we just created.
Takeaways
In this section, we:
- Went from knowing our end goal to finding our way back to our starting point.
- Learned the steps and their inter dependencies in the path from A to B.
The next section will go through how to make sense of this diagram and the useful insights you can take out of it.
Critical Path Analysis
As mentioned at the start of this document, this framework is an adaptation of the Critical Path Analysis technique, thus, we can take similar insights from it.
The first insight we want to capture is what is the minimum amount of work we can do and get away with — in other words, what is our Minimum Viable Product (MVP)? To figure that out, we start from the end and ask ourselves "what dependencies of the current step are a must?"
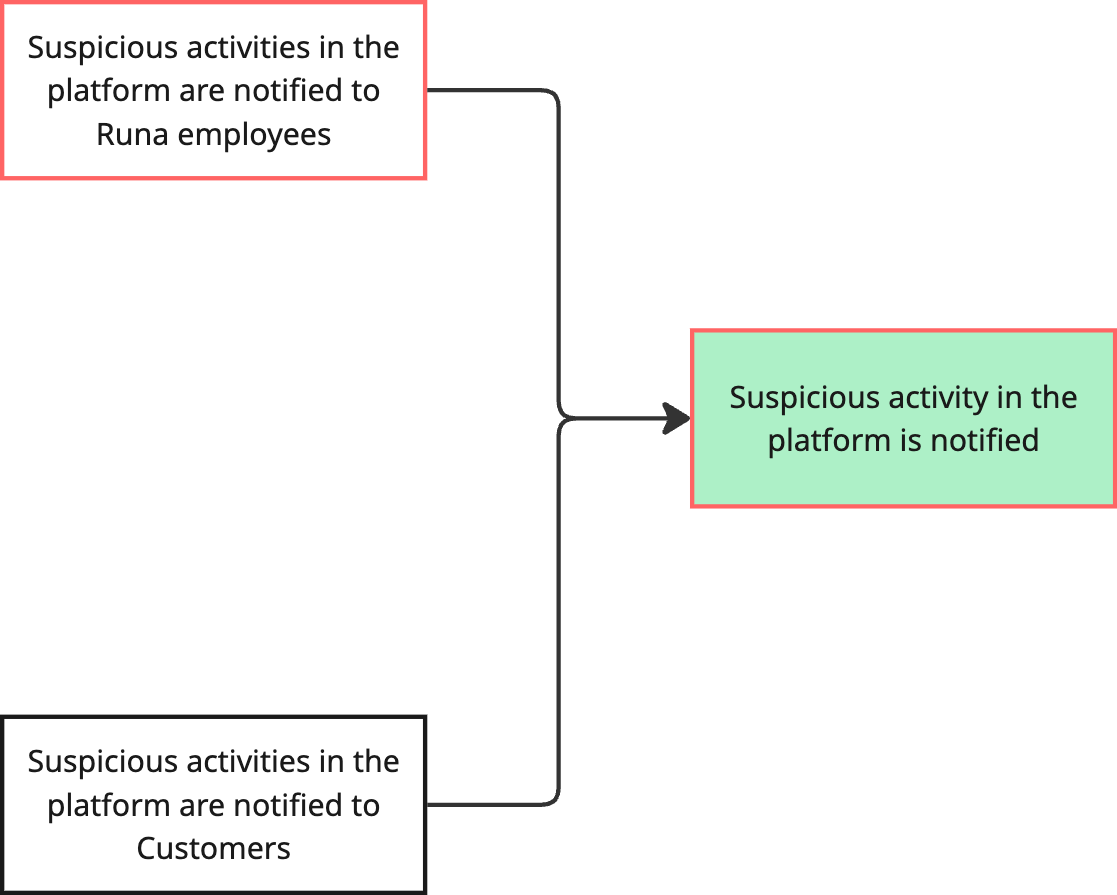
Our goal is dependant of two previous steps. In some cases they are all required, in this case we can launch an MVP with only internal notification in place and have Customer notification as part of a later milestone. We then highlight these steps in red to help us identify the critical path.
We now ask ourselves the same thing on every step that is highlighted in red. What dependencies are a must for the company's employees to be notified? Since it only has one dependency, we can highlight it and move one step back again.
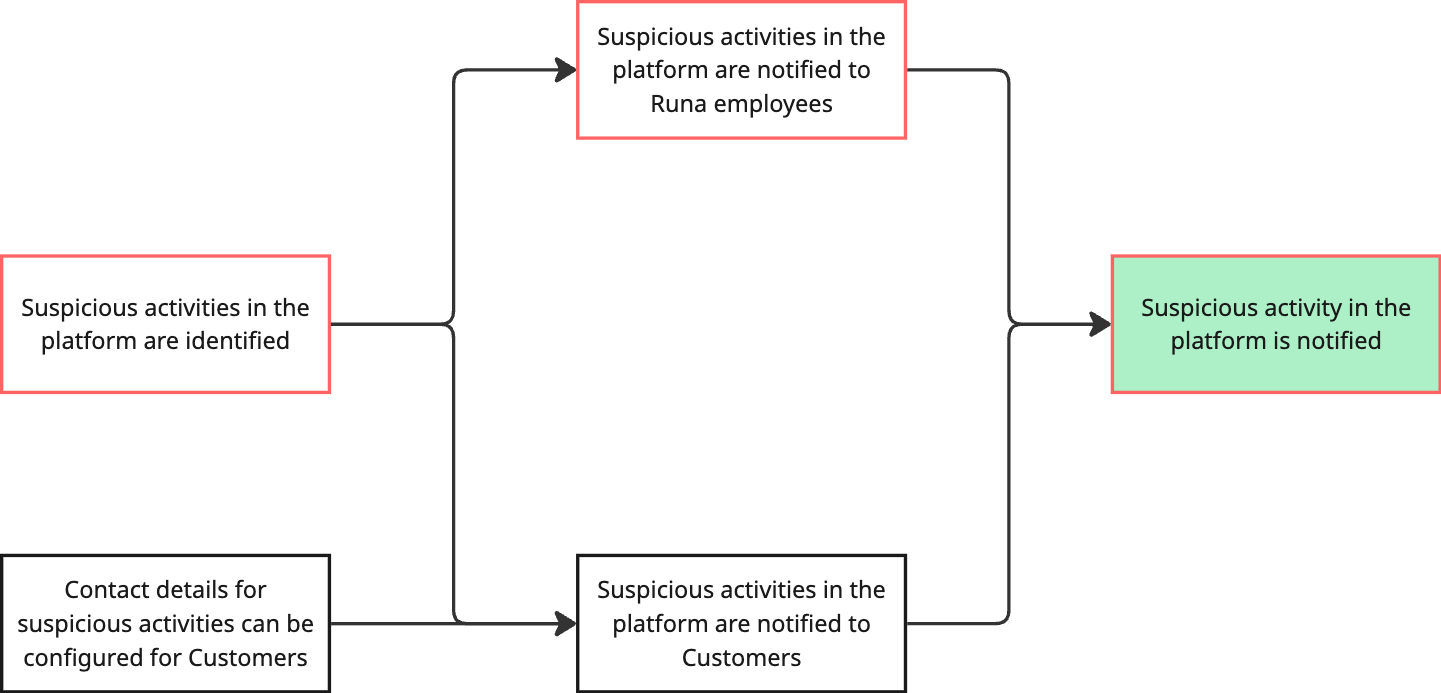
We now get to a step with 3 separate previous steps. As we said before, they might all be required or just a few. In this case, we do not need to be able to configure thresholds to be able to put an MVP live — these thresholds can be hardcoded, initially. But we do need to analyse the data, even if that algorithm is not as sophisticated as the eventual final solution.
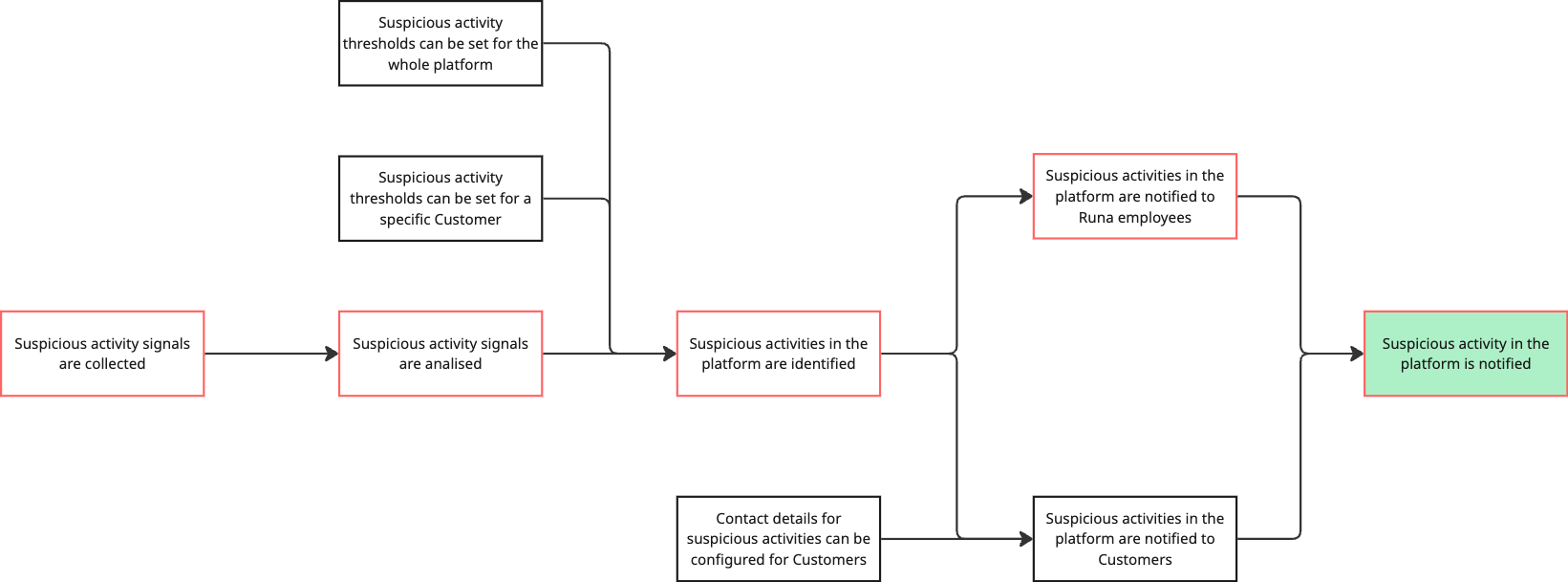
Again, we get to a point where we have 3 separate previous steps. This is an interesting one since the work to apply them is already in place (our starting points) and we just need to connect them. It might be tempting to mark them all as part of the critical path, but resist the temptation. Remember we are defining our MVP and want to get away with the least amount of work necessary. To that end, can we pick one of the data sources and work with it? Yes we can.
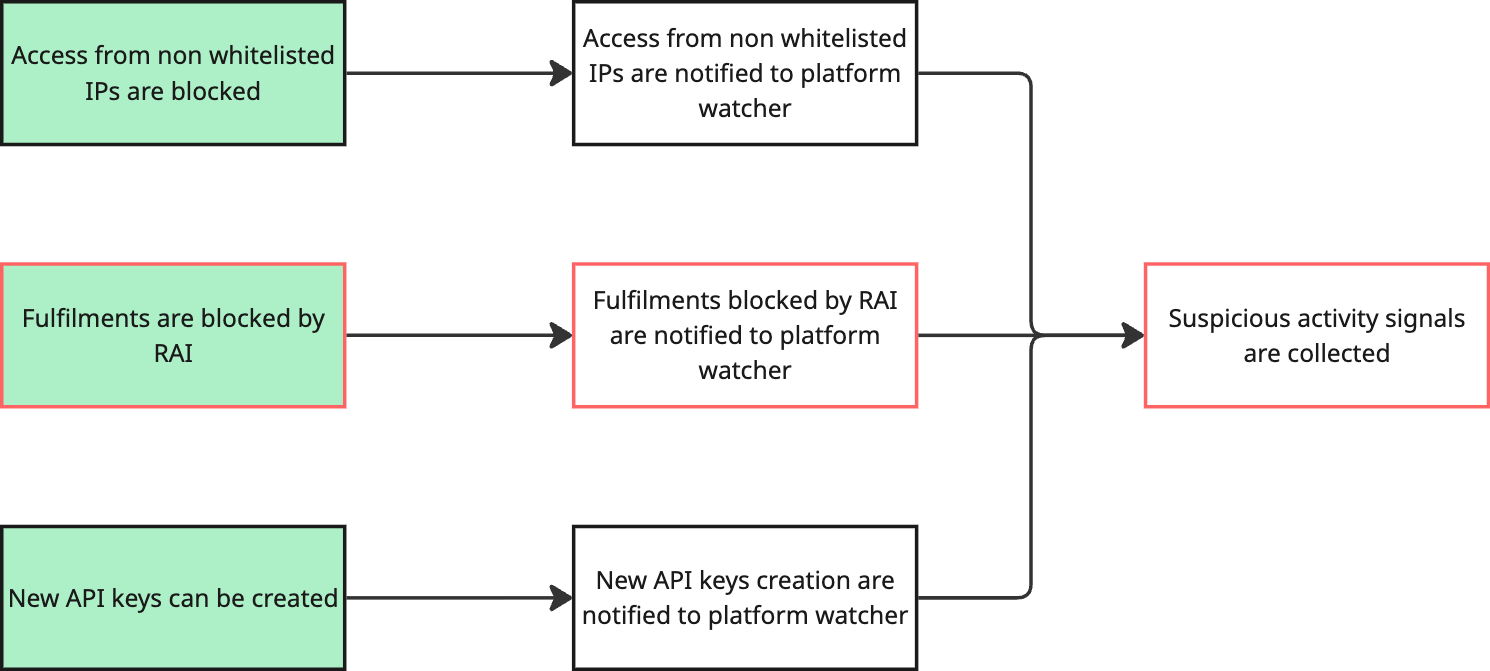
We now have our critical path going from A to B.
Takeaways
In this section, we:
- Learned the critical path within our strategy.
- Learned what is a must for our MVP.
- Learned what can be left for later.
The next section will go through how to turn this diagram into milestones you can start working on.
Milestone breakdown
When planning milestones for your delivery, you need to slice your strategy into smaller chunks that contribute to your end goal. The first milestone is usually easy to define — use the steps in your critical path as the components of your MVP.
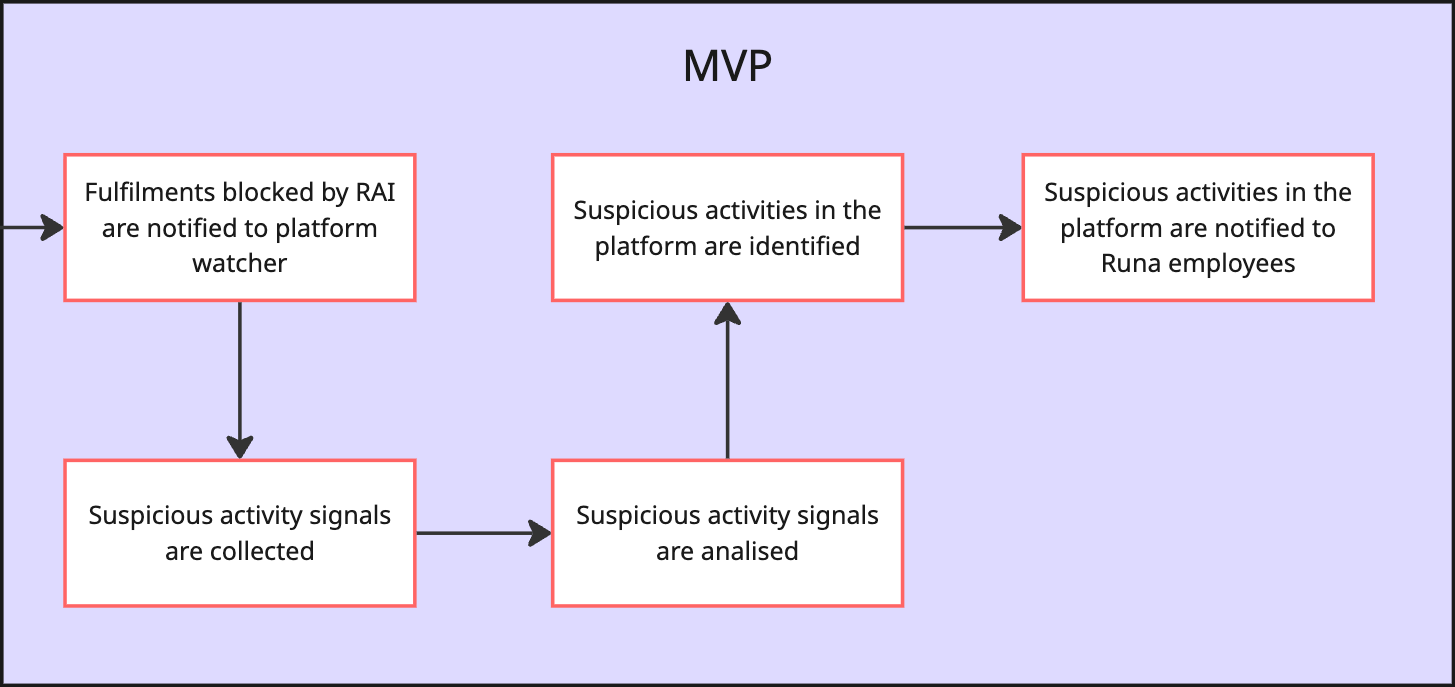
For your next milestones, you need to separate the remaining steps into groups that deliver complete (or usable) use cases. These groups might have inter dependencies between them, or they might be isolated from each other. Either way, you just need to sequence them and you have your milestones.
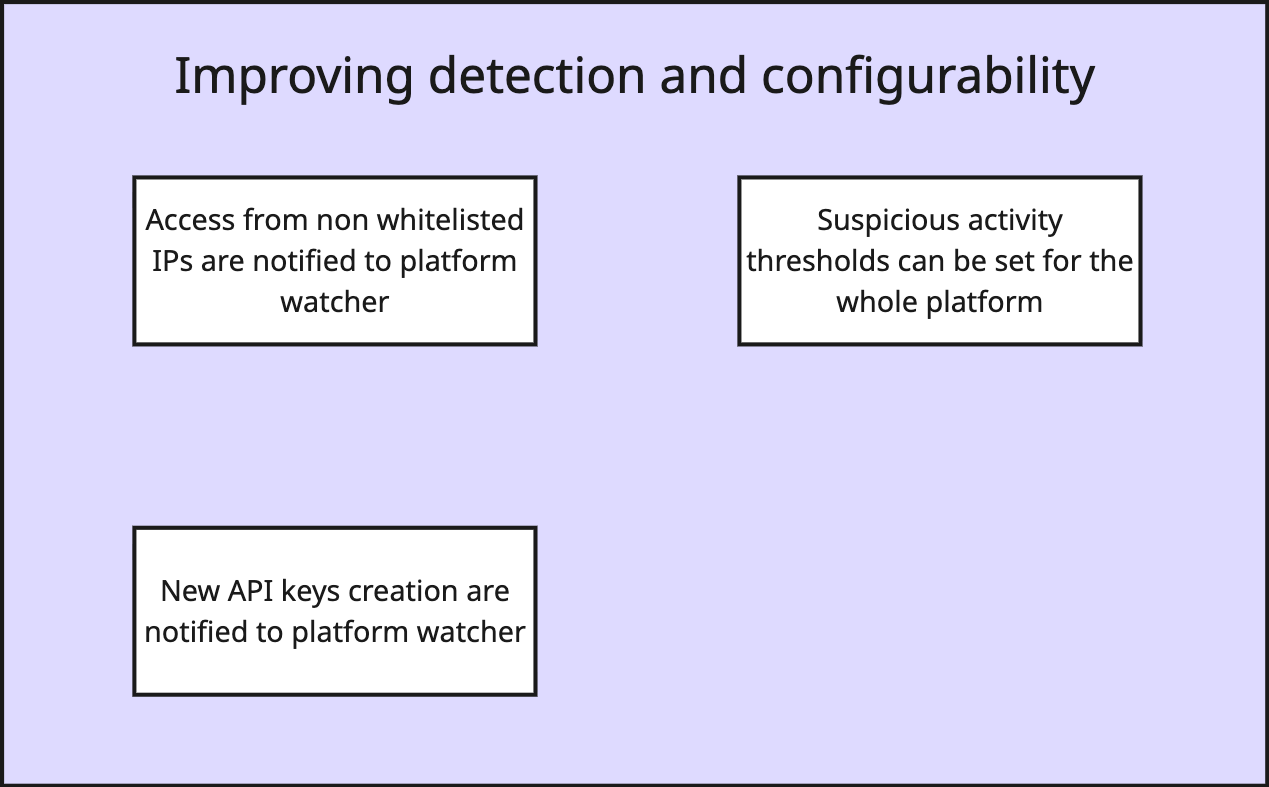
In our example, what's currently out of the MVP is:
- Customer notification
- More signals for our analysis algorithm
- Configurability for the whole solution
You can put these in whatever sequence, but it would make sense to leave the Customer notification to the end, once we have more confidence in the solution. With that in mind, our next milestone will be the improvement of detection and configurability.
Now we put together our last milestone: notifying customers.
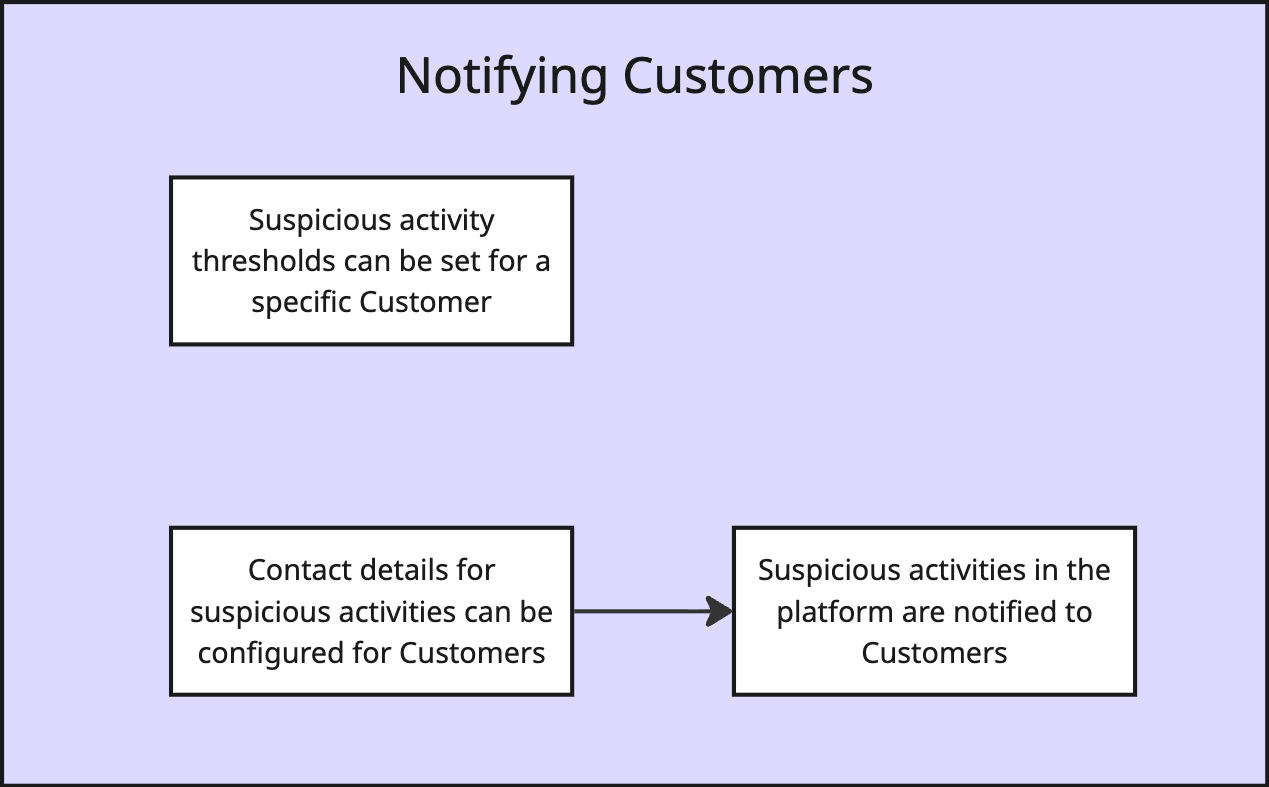
And this takes us to a complete plan:

Takeaways
In this section, we:
- Broke down our initiative into smaller deliverables that ensure we get constant feedback and have multiple pivot points before the final delivery.
- Made sure no work will be done before its dependencies are completed.
Acting the plan out
At this point, you already have your path laid out to you in two formats: critical path analysis and milestone breakdown. Now you need to dive into each step and break it down into stories your team can work on.
What is unclear to us?
This should always be your first question. When looking at your plan, what is unclear? What are you not quite sure how to accomplish? Is it the contract of the data ingestion? Is it the analysis algorithm? Are there any prior art in these problems within your company? Bring experts in if you have them around, if not, these are great candidates for design sprints and experimentation.
What are the boundaries of your plan?
No matter how high or low level your plan is, you always have components within it that have a boundary in between them. Define these boundaries and contracts early! Having them defined at the start of your initiative allows you to move forward, and in parallel, much earlier. You can always go back and refine the contracts later. But having something in place gives everyone a starting point and the ability to work on their own problem space without worrying about what is behind the contracts. For example, what is the contract between the Fraud Watcher and the rest of the platform? How will data ingestion work?
What can be parallelised?
This question applies to multiple levels of your plan. What stories, milestones, cross-team-epics can be worked in parallel? Once you define your contracts, you can get started in multiple steps at the same time, even if there is a dependency between them. It means that you don't need to wait for A to be completed before you start B. You can start A and B in parallel, with the caveat that B will only be truly finished once A is. But if you have spare capacity in your team, this is a great way to get a head start in your next story or even milestone.
Final takeaway
As I mentioned at the start of this document, this is not the only way to plan initiatives. But it is a way that works for me and might work for you. Take from this what you think is useful and twist it into something that applies to your situation. This is a starting point for you to wrap your head around large scale planning, not the definitive guide on how to do it. Look through the useful links, specially the examples, and you will notice that even I don't always apply this the same way.
Always ask yourself "where are we?" and "where do we want to get to?" — that will give you the best frame of mind before any planning, no matter the method.
Useful links
- Critical Path Analysis in two lenses
- Similar (or the same if you squint your eyes) technique
- How to read a book — this might seem unrelated, but I guarantee that the first chapters will make you read anything you put your hands onto differently; from books, to scientific papers, to diagrams, and project planning.